
이번 글에서는 프로세스와 스레드에 대해, 그리고 차이점을 얘기하겠습니다.
추가로, 프로세스 구조에 대해 간단히 다룰 예정입니다.
프로세스와 스레드
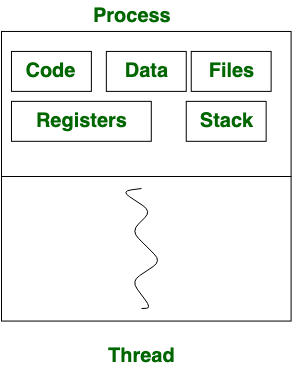
프로세스와 스레드는 둘다 "단위" 개념입니다.
프로세스란 프로그램이 실행되면서 운영체제에 의해 필요한 주소 공간, 메모리 등의 시스템 자원을 할당받고, 여러 작업을 처리하게 되지요. 이때의 작업 단위가 입니다.
스레드는 한 프로세스 내에서 작업을 분산해서 효율적으로 처리하는 실행의 단위입니다. 결국, 프로세스 하나에서 자원을 공유하면서 일련의 과정을 수행하는 것입니다. (멀티 스레드 환경으로 구성되어야 효율성 향상을 경험할 수있습니다.)
좀더 구체적으로 이야기하면,
💡 프로세스
먼저 프로세스가 실행되기 위해서는 메모리 할당이 이루어지고, 할당된 메모리 공간으로 바이너리 코드가 올라갑니다. 이것을 프"로세스" 라고 부릅니다.
그리고 OS는 *프로세스 스케줄러를 이용해서 하나의 프로세스를 선택해 CPU를 할당합니다.
스케줄링된 프로세스는 *준비(ready) 상태에서 실행 상태로 넘어갑니다.
OS는 프로세스 스케줄러를 이용해서 하나의 프로세스를 선택해 CPU를 할당합니다. (=> 프로세스 상태 전이)
*프로세스 상태 변화
① Admit (생성->준비)
프로세스가 실행되면 모든 프로세스는 OS 커널에 존재하는 준비 큐(Ready Queue)에 들어갑니다.
② Dispatch (준비->실행)
준비 큐에 있는 프로세스들 중에서 OS는 프로세스 스케줄러를 이용하여 실행 상태로 가야 할 하나의 프로세스를 선택하여 CPU를 할당한다.
③ Timer Run out (실행->준비)
CPU를 할당받은 프로세스가 주어진 사용시간을 다 쓴 경우,
CPU 스케줄링에 따라 우선순위가 높은 프로세스에게 CPU를 양보할 경우 발생합니다.
④ Blocked (실행->슬립)
CPU를 할당 받은 프로세스가 입출력(I/O) 이벤트를 요구하거나 CPU 이외의 서비스를 요구할 때 발생합니다.
⑤ Wake up (슬립->준비)
입출력(I/O) 이벤트나 그 외 서비스 처리가 끝났을 때 발생합니다.
⑥ Release (실행->종료)
프로세스 종료
*CPU 스케줄러
OS는 프로세스 실행 결정 및 필요한 자원을 할당하는 작업 스케줄러(Job Schedulaer)와
프로세스 상태 전이(Process State Transition)를 제어하는 프로세스 스케줄러(Process Scheduler)
두 종류의 CPU 스케줄러를 사용합니다.
예를 들면,
제 컴퓨터의 운영체제는 현재 IntelliJ IDE도 돌리고 있고, Chrome도, 스티커 메모도, 카카오톡도, 디스코드도, 안랩도..등등등.. 많은 프로그램을 실행시켜 프로세스를 돌리고 있습니다.
즉, 프로그램들을 실행시킨 상태가 프로세스입니다.
✋ 동시성과 병렬성
동시성은 2개 이상의 작업이 있을 때 서로 다른 작업의 실행 시점에 상관없이 작업 실행이 가능하다는 의미를 가집니다.
싱글 코어에서 멀티 스레드를 동작시키는 방식이 예입니다.
이를 *Context Switching이라고 부릅니다.
병렬성은 2개 이상의 작업이 있을 때 각 작업이 물리적인 시간으로 동시에 실행이 가능하다는 의미를 가집니다.
멀티 코어에서 멀티 스레드를 동시에(병럴적으로) 동작시키는 방식이 예입니다.
*Context Switching
- CPU가 이전 상태의 프로세스를 PCB에 보관하고, 또 다른 프로세스를 *PCB에서 읽어 레지스터에 적재하는 과정
- 사실 눈으로 보기에는 여러 프로세스들이 동시에 진행되는 것처럼 보이지만 실제로는 CPU가 여러 프로세스를 돌아가며 하나씩 처리하는 것입니다. (CPU는 한 번에 하나의 프로세스만 실행합니다.)
In computing, a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point. This allows multiple processes to share a single central processing unit (CPU), and is an essential feature of a multitasking operating system. (By Wikipedia)
CPU에 의해 동작중인 Task(프로세스 or 스레드)가 대기를 하면서 Task의 상태(Context)를 보관하고 대기하고 있다가 다시실행 시 상태를 복원하여 실행을 재개하는 방식입니다.
Context Switching 기법 덕분에 단일 CPU를 여러 프로세스/스레드가 공유할 수 있어, 멀티 태스킹 환경에서는 필수 기능입니다.
Context Switching이 발생하면서 (Task를 다시 복원하여 실행하는데) 많은 비용(시간)이 소요됩니다.
프로세스와 스레드 모두 Context Switching이 일어나는데 프로세스가 스레드보다 더 큰 비용이 발생합니다.
프로세스는 각 프로세스가 독립적이고 개별 메모리를 차지하기 때문에 매 Switching마다 상태값(캐시, 메모리 매핑 등)을 해당 Task의 상태값으로 바꿔줘야 합니다.
반면, 스레드는 스레드들끼리 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 Context Switching 발생 시 Stack 영역만 변경하면 됩니다.
💡 스레드
동시성과 병렬성 작업처럼 프로세스들을 동시에, 혹은 번갈아 수행할 수 있게 되었습니다.
하지만.. 한 프로세스에서도
게임을 다운받으면서, 게임 사이트를 구경하고
유투브 영상을 볼 때도 데이터를 받아오면서 영상을 실행해야합니다.
즉, 한 프로세스에서도 여러 개의 작업들이 동시에 진행됩니다. 이러한 작업을 효율적으로 처리하기 위해 스레드 가 등장합니다.
사실 프로세스가 여러 스레드를 가질 수 있으며 여러 스레드가 프로세스 내에 포함되어 있기 때문에 스레드는 프로세스의 세그먼트(segment)로 볼 수 있습니다.
결론적으로 운영체제는 프로세스마다 자원을 분할해서 할당하는데, 각 프로세스 내에서 할당받은 자원을 스레드들이 함께 공유하며 작업을 처리하게 됩니다.
🗣️ 차이가 무엇인가? (정리)
| 프로세스 (Process) | 스레드 (Thread) |
| Process는 어떠한 실행 중인 프로그램이다. | Thread는 Process의 세그먼트이다. |
| 종료/생성하는데 시간이 더 걸린다. | 종료/생성하는데 시간이 덜 걸린다. |
| context switching에 더 많은 시간이 걸린다. | context switching에 더 적은 시간이 걸린다. |
| 커뮤니케이션 측면에서 덜 효율적이다. ➕ *IPC (Inter-Process Communication) |
커뮤니케이션 측면에서 더 효율적이다. (보통 프로세스 내에 멀티 Thread로 구성된다. 그래야 효율이 있다) |
| 독립적이다. (다른 프로세스들과 메모리를 공유하지 않는다) | 메모리를 공유한다. (Process 내 각 Thread는 code, data, resources을 공유한다.) |
| System Call (Process 변환은 OS의 인터페이스 사용) |
Library Call (Thread 전환 시 OS를 호출하지 않고, 커널에 interrupt 발생) |
| 만약 process가 중단되도다른 process 수행에 영향을 미치지 않는다. ex) Chrome |
*user-level Thread가 중단되면, 모든 다른 user-level Thread가 중단된다. ex) internet explore |
| 각각의 *PCB, 스택, 주소 공간을 가지고 있다. | 부모의 PCB, 자신의 TCP, 스택, 공유하는 주소 공간을 가지고 있다. |
| 부모 Process의 변화가 자식 Process들에게 영향을 미치지 않는다. | 같은 Process의 모든 Thread는 주소 공간과 기타 resources를 공유하기 때문에 메인 스레드의 변경이 다른 스레드 동작에 영향을 미칠 수 있다. |
*Process Control Block (PCB) : 운영체제가 프로세스를 제어하기 위해 프로세스의 상태 정보를 저장하는 구조체
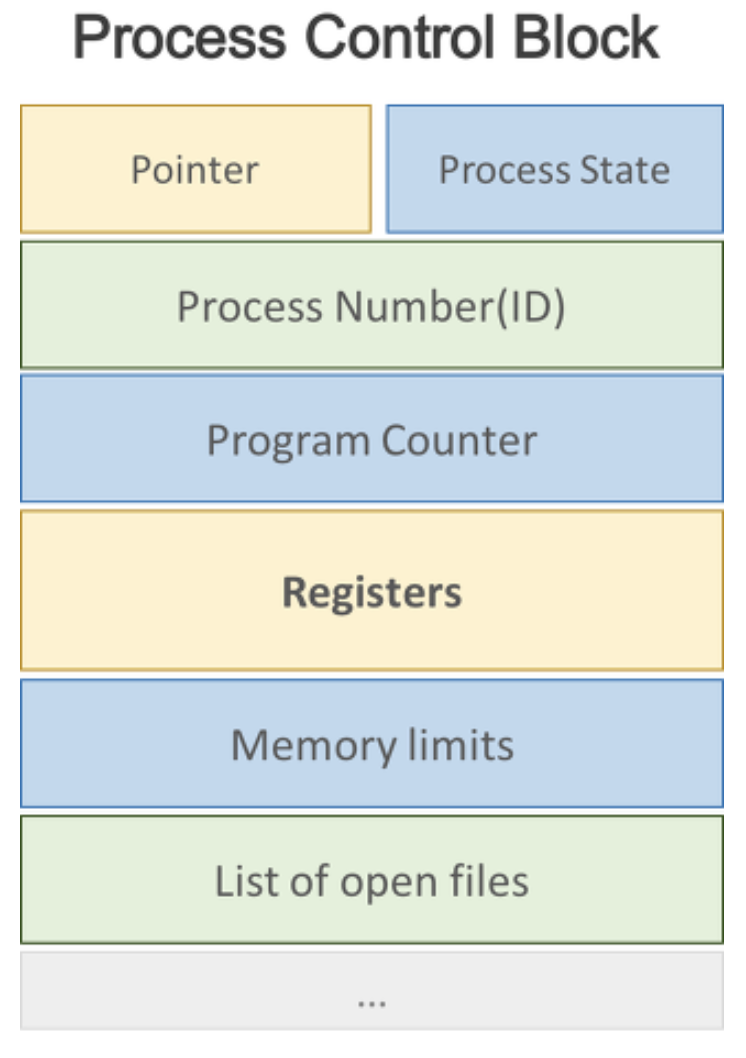
- 결국 운영체제라는 프로그램이 프로세스를 실행하려면, 그 프로세스의 상태 및 중요 정보를 담는 데이터 구조가 있어야합니다. 그 정보들을 저장해놓고 필요할 때 사용하는 저장 장소가 PCB입니다.
- 프로세스 상태 관리와 문맥 교환 (Context Switching)을 위해 필요합니다.
- 프로세스 생성 시 만들어지며 주기억장치에 유지됩니다.
*IPC(Inter-Process-Communication)
- 프로세스 간의 커뮤니케이션을 지원하기 위한 기법
- IPC가 필요한 이유 (feat. 다른 process의 주소 공간에 접근 불가)
- 프로세스 A가 프로세스 B의 스택 공간에 접근해 임의로 값을 바꾸는 경우가 생길 수 있습니다.
- 따라서, OS에서는 다른 프로세스로의 접근을 막아두고 있습니다.
- 결과적으로, 프로세스간 통신을 위해서는 직접 접근하는 것 외의 다른 방법이 필요합니다.
- Message Passing, Shared Memory 기법
프로세스 구조 (간단히)
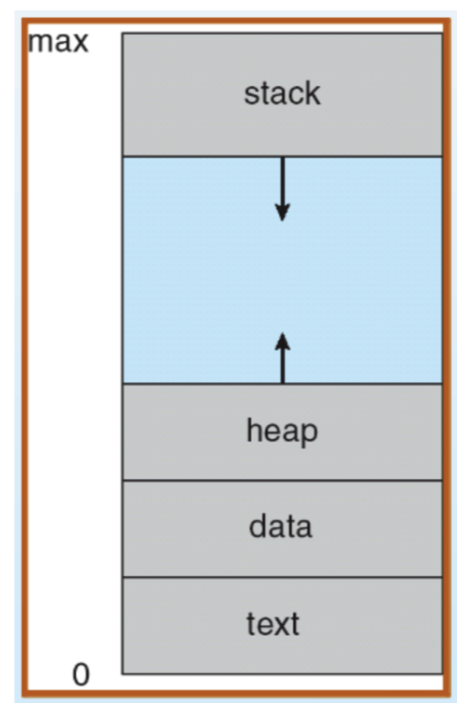

Code
컴파일된 소스 코드가 저장되는 Code 영역으로, CPU는 이 영역에 저장된 명령어를 하나씩 가져와서 수행합니다.
프로그램이 시작되고 끝날 때까지 메모리 영역에 유지합니다.
Data
전역 변수와 정적(static) 변수&배열(array) 등이 저장되는 영역으로, 프로그램이 시작될 때 할당되고 종료될 때 해제됩니다.
사실 Data 영역은 BSS와 Data 영역으로 구성되어 있습니다.
- Data 영역 : 초기화된 전역 변수가 저장
- BSS(Block Stated Symbol) 영역 : 초기화 되지 않은 전역 변수가 저장
➕ 함수 내부에 선언된 Static 변수는 프로그램이 실행 될 때 공간만 할당되고, 그 함수가 실행 될 때 초기화됩니다.
Stack
Stack은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸합니다.
함수 호출 시 생성되는 임시 데이터(함수 호출, 로컬 변수, 매개변수, 리턴 값..)를 저장하기 때문에 임시 메모리 영역이라 할 수 있습니다.
- 원시타입과 참조타입
- 원시타입 : 원시타입의 데이터가 값과 함께 할당된다. ex) int a = 3;
- 참조타입 : Heap 영역에 생성된 객체의 주소값(참조값)이 할당된다. ex) number = 1233 (주소값)
컴파일 타임에 크기가 결정되기 때문에 무한히 할당할 수 없습니다. 재귀함수가 너무 깊게 호출되거나 함수가 지역변수를 너무 많이 가지고 있어 stack 영역을 초과하면 StackOverFlow 에러가 발생합니다.
Heap
런타임에 크기가 결정되는 메모리 영역으로, 프로그래머에 의해 동적으로 할당되고 해제됩니다.
- 참조형의 데이터의 값이 저장됩니다.
- 관련 함수를 통해 동작 할당 요구를 하면 정해진 길이를 전체영역에서 일부분을 할당하고 포인터값을 넘깁니다. ex) C는 malloc(), C++은 new() 함수를 사용
⚠️ HEAP과 STACK영역은 같은 공간을 공유합니다.
STACK이 메모리 위쪽 주소부터 할당되면 HEAP은 아래쪽부터 할당되는 식입니다.
그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 Heap Overflow, Stack Overflow라고 칭합니다.
출처
공부하며 작성한 글이니 잘못된 부분이 있을 수 있습니다.
잘못된 부분 발견 시, 계속해서 수정 예정입니다.
피드백과 댓글 환영입니다!
관련 포스팅
멀티 프로세스와 멀티 스레드 (feat. 아파치와 톰캣)
관련 포스팅 프로세스(Process)와 스레드(Thread) Context Switching, IPC 등 개념은 위 포스팅에서 중간에 다뤘으므로 생략하겠습니다. 이번 글에서는 멀티 프로세스와 멀티 스레드에 대해 얘기해보려 합
thisisprogrammingworld.tistory.com
'Computer Science' 카테고리의 다른 글
| [Network] TCP/UDP (0) | 2022.04.25 |
|---|---|
| [네트워크] 프로토콜과 OSI 계층 (0) | 2022.04.25 |
| 멀티 프로세스와 멀티 스레드 (feat. 아파치와 톰캣) (0) | 2022.04.18 |
| 링킹 (Dynamic Linking vs Static Linking) (2) | 2022.02.17 |